







Gamfed Türkiye Kaptanı Beray Çinçin yazıyor: Yapay Zeka Destekli Algoritmik Oyun Tasarımı ile Kurguların Başarısını Öngörmek
Yapay Zeka Destekli Algoritmik Oyun Tasarımı ile Kurguların Başarısını Öngörmek
Oyunlaştırma uzun süre boyunca tasarımcıların sezgilerine ve deneme-yanılma yöntemlerine dayanan, daha çok kişisel yaklaşımlarla ilerleyen bir alan olarak görüldü. Eğitim, sağlık, finans, pazarlama ve insan kaynakları gibi birçok alanda ise kullanıcı motivasyonunu artırmak ve etkileşimi güçlendirmek için oyun mekanikleri kullanıldı.
Bu yaklaşımın temel sınırlaması, bir kurgunun etkili olup olmadığının ancak kullanıcı süreci tamamlandıktan sonra anlaşılmasıydı, ve bu durumda yüksek terk oranları, düşük bağlılık ve maliyetli iterasyonlara katlanma gerekliligi ortaya çıkıyordu. Bugunlerde veri odaklı yaklaşımlar ve yapay zeka ile bu paradigma zorunlu bir donusum rotasinda ilerliyor. Yapay zeka destekli algoritmik oyun tasarımı, oyunlaştırmayı ölçülebilir ve öngörülebilir bir sisteme dönüştürüyor. Tasarımcılar artık yalnızca deneyim üretmekle kalmıyor, bu deneyimin kullanıcı üzerindeki etkisini önceden modelleyebiliyor.
Örneğin, bir kurumsal eğitim platformunda şirkete yeni katılan çalışanlar için hazırlanan bir onboarding sürecini dusunelim. Bu süreçte yapay zeka destekli sistem, kullanıcıların ilerleme hızını ve etkileşim oranlarını anlık olarak izleyerek kritik kopma noktalarını tespit edebilir. Eğer kullanıcıların çoğu belirli bir görevi tamamlayamadan süreci bırakıyorsa, sistem otomatik olarak görevin zorluk seviyesini azaltır veya kullanıcıya motive edici bir sürpriz ödül sunar. Aynı zamanda farklı kullanıcı segmentleri için kişiselleştirilmiş görev dizileri önererek her bir kullanıcının devam etme olasılığını en üst seviyede tutacak sekilde bir planlama yapilabilir. Sonuç olarak, hem terk oranları hem de kullanıcı bağlılığı konusunda eski yöntemlere göre çok daha yüksek performans elde edilir.
Etkili bir oyunlaştırma deneyimi, insan motivasyonunun temel mekanizmalarını anlamakla başlar. Dopamin, bir nörotransmitter olarak, yalnızca ödülün kendisiyle değil, ayni zamanda ödül beklentisi ve bu beklentinin ne ölçüde karşılandığı ile de ilişkilidir. Bu süreç, ödülün beklenen ve gerçek değerleri arasındaki fark anlamına gelen Reward Prediction Error (RPE) olarak tanımlanır. RPE, kullanıcının zihnindeki beklenti ile sistemin sunduğu gerçek sonuç arasındaki farktır.
Pozitif RPE, bir eylemin sonucunda alınan ödülün beklenenden daha yüksek veya daha kaliteli olduğu durumlarda ortaya çıkar. Beyin bu durumu “Beklediğimden daha iyi” şeklinde algılar. Bu sinyal sadece anlık haz ile ilgili değildir. Aynı zamanda öğrenme ve davranış önceliklendirme sürecinin bir parçasıdır. Oyunlaştırılmış bir kurguda bu durumu kullanıcının standart bir ödül beklerken aniden o anlik akisin dışında bir “bonus” kazanması veya beklemediği bir anda takdir edilmesi gibi örneklerle gozlemleyebiliriz. Pozitif RPE, beynin ödül merkezini güçlü şekilde uyarır ve davranışın tekrar edilme olasılığını artırır. Kullanıcı, bu dopamin artışını tekrar yaşamak için aynı eylemi yapmaya daha istekli olur.
Negatif RPE, beklenen bir ödülün gelmemesi veya beklenen düzeyin altında kalması durumudur. Beyin bu durumu “Bir şeyler ters gidiyor” veya “Tahminim hatalı” olarak algılayarak duraksayabilir. Bu sessizlik, beyin için “hata sinyali” olarak yorumlanabilir ve prefrontal korteksi (karar verme merkezi) uyararak mevcut stratejinin işe yaramadığını bildirir.
Oyunlaştırma kurgusunda bir görevi tamamlamasına rağmen puan alamayan veya yanlış strateji yüzünden seviye kaybeden kullanıcınin yasadigi durum buna ornek gosterilebilir.
Negatif RPE olumsuz deneyim çağrışımı yapsa da, her zaman kötü değildir; doğru kurgulandığında “Bilişsel Esneklik” yaratır. Kullanıcı, neden başarısız olduğunu anlamak için çevresine daha fazla dikkat kesilir ve hatasını düzeltmek için yeni yollar aramaya başlar. Sistem, kullanıcıyı ezbere gitmek yerine öğrenmeye ve strateji geliştirmeye zorlar. Ancak negatif RPE çok sık tekrarlarsa, öğrenme isteği yerini çaresizliğe ve sistemden kopuşa (churn) bırakır.
- Pozitif RPE: Gerçek ödül beklentinin üzerindedir → Motivasyon ve tekrar etme isteği artar.
- Negatif RPE: Ödül beklentisinin altındadır → Dikkat ve öğrenme süreci tetiklenir. Sistemi ciddiye almayı ve stratejik düşünerek öğrenmeyi sağlar.
Başarılı bir tasarımda bu iki hata sinyali dengeli bir şekilde kullanılarak kullanıcınin akış (flow) içerisinde tutulmasi hedeflenir.
Bu mekanizma sürdürülebilir motivasyonun anahtarıdır. Sabit ödül sistemleri hızla monotonlaşırsa, rastgele sistemler güveni zedeleyebilir. En etkili deneyimler, öngörülebilirlik ile belirsizlik arasında dengeli bir yapı kuran deneyimlerdir. Modern oyunlaştırma tasarımı: beklenen küçük ödüllerle temel motivasyonu korur, stratejik sürprizlerle pozitif RPE yaratır ve kontrollü sapmalarla öğrenme döngüsünü canlı tutar.
AI destekli sistemler bu nörobiyolojik döngüleri modelleyerek veri kalitesi, bireysel farklılıklar gibi dinamiklerin dikkate alınmasıyla kullanıcı davranışını yüksek doğrulukla öngörebilir. Kullanıcı motivasyonu ve davranışsal parametrelerin ölçümü için çoklu veri toplama yolları kullanılır. Bunlar arasında uygulama içi etkileşimlerin (tıklamalar, görev tamamlama oranları, geçmiş başarımlar), süre analizlerinin (oturum süresi, işlem aralıkları), doğrudan anket ve geri bildirim formlarının yanı sıra ısıl haritalar veya davranışsal izleme araçlarıyla toplanan detaylı kullanıcı hareketleri bulunur. Ayrıca A/B testleri ve kullanıcı segmentasyonuna dayalı deneysel analizler, farklı motivasyon eşiği ve ödül adaptasyon seviyelerinin tespitinde kullanılır. Böylece kullanıcının motivasyon eşiği, sıkılma noktası, ödül adaptasyonu ve bilişsel yük toleransı gibi parametreler sistematik olarak analiz edilir. Bu noktada AI, yalnızca rasyonel karar kalıplarını değil, davranışsal ekonominin ortaya koyduğu sistematik irrasyonel eğilimleri de modelin bir parçası haline getirir. Bu davranışsal eğilimler, çoğu zaman kullanıcının bilinçli farkındalığının dışında çalışır ve karar süreçlerini sistematik olarak etkiler.
Örneğin, loss aversion (kayıptan kaçınma) prensibine göre kullanıcılar bir kazanç elde etmekten ziyade mevcut kazanımlarını kaybetmemek için daha güçlü bir motivasyon hisseder. Bu nedenle sistemler kazanılmış rozetlerin veya ilerleme seviyelerinin kaybedilme riskini (örneğin streak mekanikleri) kullanarak bağlılığı artırabilir.
Benzer şekilde, sunk cost fallacy (batık maliyet yanılgısı) kullanıcıların daha önce harcadıkları zaman ve emeği gerekçe göstererek sistemi terk etme olasılıklarını düşürür. AI modelleri, kullanıcının geçmiş yatırımını (tamamlanan görevler, harcanan süre vb.) dikkate alarak, kritik terk noktalarında bu yatırımı görünür kılan teşvikler sunabilir.
Sosyal davranışlar da bu modelin önemli bir parçasıdır. Sosyal onay (sosyal onay) ihtiyacı, kullanıcıların başkaları tarafından tanınma ve takdir edilme isteğini ifade eder. Liderlik tabloları, başarı paylaşımları veya ekip içi görünürlük gibi mekanikler bu ihtiyacı hedef alır. AI hangi kullanıcıların sosyal geri bildirime daha duyarlı olduğunu analiz ederek bu tür mekanikleri kişiselleştirebilir.
Buna ek olarak, variable reward (değişken ödül mekanizması) ödüllerin sabit değil belirsiz aralıklarla sunulmasının kullanıcı bağlılığını önemli ölçüde artırdığını gösterir. Beklenmeyen ödüller, dopamin sistemini daha güçlü tetikleyerek tekrar davranışını pekiştirir. AI sistemleri, kullanıcının alışkanlık geliştirme sürecine göre bu ödül dağılımını dinamik olarak ayarlayabilir.
Bir diğer önemli etki ise Endowed Progress Effect (başlangıç avantajı etkisi) olarak bilinir. Kullanıcılar bir hedefe zaten kısmen ilerlemiş olduklarını hissettiklerinde, o hedefi tamamlama olasılıkları önemli ölçüde artar. Bu nedenle sistemler kullanıcıya başlangıçta “önceden kazanılmış” küçük ilerlemeler sunarak motivasyonu hızlandırabilir. AI hangi kullanıcıların bu tür başlangıç avantajlarından daha fazla etkilendiğini analiz ederek onboarding süreçlerini optimize edebilir.
Bu davranışsal modelleme katmanı algoritmik karar sistemlerinin temelini oluşturur. Bu sayede yapay zekâ, yalnızca kullanıcının ne yaptığını değil, neden o şekilde davrandığını da anlamlandırarak daha isabetli ve bağlama duyarlı tahminler üretebilir.
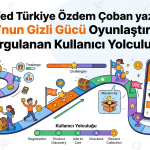
Algoritmik oyun tasarımının yapay zekayı tasarımın aktif bir bileşeni olarak konumlandırması gerekir. Bu sistemlerin temelinde: sağkalım analizi (verilerin ne kadar süre hayatta kaldığını inceleyen istatistiksel yöntem), lojistik regresyon (olayların gerçekleşme olasılığını tahmin eden model), karar ağaçları (karar alma süreçlerini modelleyen şematik yapı) ve pekiştirme öğrenme (bir ajanın ödül-ceza yoluyla optimum davranışı öğrenmesini sağlayan algoritma) gibi güçlü analitik modeller yer alır.
- Sağkalım Analizi (Survival Analysis): Kullanıcının sistem içinde ne kadar süre “hayatta kalacağını” (yani aktif olacağını) ölçer. Sadece kullanıcının ayrılıp ayrılmadığına değil, ne zaman ayrıldığına odaklanır ve çeşitli araçlarla kullanıcıların hangi gün veya hangi seviyede pes ettiğini gösteren bir zaman çizelgesi çıkarır. Oyunlaştırılmış kurguda “Kullanıcılar genellikle 4. günde sıkılıyor” benzeri net veriler sunarak, tam o kritik anda (4. gün gelmeden) kullanıcıyı sistemde tutacak bir “pozitif RPE” (sürpriz ödül) kurgulamanıza imkân tanır.
- Lojistik Regresyon ve Karar Ağaçları (Churn Prediction): Bu modeller, kullanıcıların sistemi neden terk ettiğini (churn) anlamak için kullanılan sınıflandırma algoritmalarıdır. Bir kullanıcının uygulamayı terk etme olasılığını 0 ile 1 arasında bir skor olarak hesaplayabilmek için lojistik regresyondan faydalanılır. Örneğin, “son 3 güne girmemiş” ve “hiç arkadaş eklememiş” bir kullanıcının ayrılma ihtimali %85 (örneklendirilmiş veri) diyebilir. Kullanıcı davranışlarını dallara ayırarak analiz edebilmek için karar ağaçlarından yararlanılır. “Eğer kullanıcı 10. Seviyeye gelmişse ve profil fotoğrafı yoksa %60 (örneklendirilmiş veri) ihtimalle bırakacaktır gibi mantıksal kurallar çıkarır. İki model de oyunlaştırma kurgularını terk etme riski yüksek olan kullanıcıları henüz ayrılmadan tespit edip, onlara özel kişiselleştirilmiş görevler veya teşvikler sunarak kaybı (churn) önlemenizi sağlar.
- Pekiştirmeli Öğrenme (Reinforcement Learning) ve Multi-Armed Bandit: Bu iki modelin birlikte kullanımı, sistemin kendi kendine öğrenerek en uygun ödül ve zorluk stratejisini dinamik olarak belirlemesini sağlar. Pekiştirmeli öğrenmede, bir yapay zekâ ajanı kullanıcının tepkilerine göre sürekli denemeler yapar ve elde ettiği geri bildirimlere göre stratejisini günceller. Örneğin, bir kullanıcıya daha zor bir görev verildiğinde sistemde daha fazla vakit geçiriyorsa (bu sistem için bir ödüldür), AI benzer profildeki kullanıcılar için zorluk seviyesini kademeli olarak artırmayı öğrenir.
Reward (ödül) fonksiyonunun tasarımı kritik bir unsur olarak göze çarpar. Bu nedenle ödül fonksiyonu genellikle tek bir metrik yerine, birden fazla hedefin dengelendiği çok boyutlu bir yapı olarak tasarlanır. Bu yapı çoğu zaman kısa vadeli etkileşim ile uzun vadeli kullanıcı değeri arasında bir denge kurmayı hedefler. Yanlış tanımlanmış bir ödül fonksiyonu, sistemin istenmeyen davranışları optimize etmesine neden olabilir. Örneğin, yalnızca “sistemde geçirilen süreyi” maksimize etmeye odaklanan bir yapı, kullanıcıya gerçek değer sunmak yerine bağımlılık benzeri davranışları teşvik edebilir. Bu nedenle pekiştirmeli öğrenme sistemleri, yalnızca performans değil, kullanıcı esenliği ve etik sınırlar gözetilerek tasarlanmalıdır.
Multi-Armed Bandit modeli ise “sınırlı kaynakla, belirsiz seçenekler arasından en yüksek kazancı elde etme” problemini çözerken, sistemin keşif (exploration) ve sömürü (exploitation) dengesini kurmasını sağlar. Sistem, bir yandan halihazırda iyi performans gösteren ödül stratejilerini kullanırken, diğer yandan yeni ve potansiyel olarak daha etkili seçenekleri test eder.
Bu yaklaşımın daha gelişmiş bir versiyonu olan Contextual Bandit modelleri, karar sürecine kullanıcı bağlamını da dahil eder. Sistem, her kullanıcıyı tek tip değerlendirmek yerine, davranış geçmişi, motivasyon seviyesi ve etkileşim alışkanlıkları gibi sinyalleri analiz ederek farklı ödül stratejileri uygular. Örneğin, rekabet odaklı bir kullanıcıya daha zor ve yüksek ödüllü görevler sunulurken, düşük motivasyonlu bir kullanıcıya daha hızlı geri bildirim ve küçük kazanımlar sağlayan görevler önerilebilir.
Bu bütünsel yapı sayesinde ödül ve zorluk seviyeleri statik kurallardan çıkarak her kullanıcının anlık durumuna, beceri seviyesine ve motivasyon eşiğine göre dinamik olarak optimize edilir. Bu yapının pratikteki karşılığını bir İnsan Kaynakları (HR) platformu üzerinden düşünelim: Yeni başlayan çalışanlara sunulan onboarding sürecinde sistem, her çalışanın etkileşim hızını, görev tamamlama oranını ve geri bildirimlerini analiz eder. Hızlı adapte olan bir çalışan için sistem, daha karmaşık görevler ve rekabetçi unsurlar (örneğin liderlik tabloları) devreye alırken, daha yavaş adapte olan bir çalışan için süreci mikro görevlere bölerek daha sık ve küçük ödüller sunar. Aynı anda Multi-Armed Bandit yaklaşımı hangi ödül tipinin (rozet, geri bildirim, görünürlük, vb.) daha etkili olduğunu test ederken, Contextual Bandit modeli bu kararları çalışanın bireysel bağlamına göre optimize eder. Bu tür adaptif sistemlerde, görev tamamlama oranı ve platform içi etkileşim sürecinde anlamlı artışlar gözlemlenebilir.
Algoritmik tasarımın başarısı, sadece bağlılığı artırmakla değil, kullanıcının psikolojik güvenliğini ve esenliğini korumakla ölçülür. Bu sistemler, çoğunlukla kullanıcıyı manipüle ederek bağımlılık yaratmak için değil, kişisel gelişimi desteklemek için optimize edilir. Tasarımın şeffaf olması ve veri gizliliği (GDPR/KVKK) standartlarına uyum sağlaması, kullanıcı güveninin sarsılmaması için önem arz eder.
Algoritmik oyun tasarımının en güçlü yönlerinden biri, gerçek kullanıcılar gelmeden önce sistemin çıktıları ile ilgili erken sinyal üretebilmesidir. Rekabet odaklı kullanıcılar, keşif arayanlar, düşük motivasyonlu bireyler gibi farklı davranış profillerine sahip yapay ajanlar (AI Agents) aracılığıyla sistemin zayıf noktaları tasarım aşamasında tespit edilir.
Örneğin, bir dijital onboarding platformunda rekabetçi ajanlar hızlı ilerlerken, düşük toleranslı ajanlar erken terk sinyali verebilir. AI bu verileri kullanarak görev zorluklarını dengeler, ödül dağılımını optimize eder ve ilerleme hızını kişiselleştirir. Önemli bir not olarak, bu düzeyde hassas öngörüler yapabilmek için sistemin yüksek çözünürlüklü kullanıcı verisine ihtiyaç duyduğu unutulmamalıdır; veri derinliği ne kadar artarsa, simülasyonun gerçekliği o kadar yükselir.
Geleneksel İnsan Kaynakları sistemleri, doğası gereği sistem kullanıcılarına “tek tip” bir deneyim sunar; bu da heterojen yetkinlik setlerine sahip ekiplerde motivasyon kırılmasına neden olabilir. Algoritmik oyun tasarımı, bireysel farklılıkları birer veri girişine dönüştürerek deneyimi kişiselleştirir. Yapay zekâ, düşük yetkinlik seviyesindeki bir çalışanda “bilişsel aşırı yüklenme” veya “stres riski” ön gördüğünde, sistemdeki rekabet unsurlarını (liderlik tabloları gibi) geçici olarak pasifize eder. Kullanıcı sistemin sunduğu mikro görevlerle yetkinlik eşiğini aştığında ise rekabet mekanizmaları kademeli olarak devreye alınır. Bu dinamik zorluk dengesi (Dynamic Difficulty Adjustment), organizasyonlara üç stratejik avantaj sağlar:
- Algoritmik Öngörülebilirlik: Tasarım aşamasında gerçekleştirilen ajan tabanlı simülasyonlar sayesinde, kullanıcı davranışları ve sistemdeki olası tıkanma noktaları saha uygulamasına geçilmeden yüksek doğrulukla tahmin edilir.
- Operasyonel Verimlilik ve Risk Yönetimi: Geleneksel “deneme-yanılma” süreçlerinin yerini “veriye dayalı doğrulama” alır. Bu, hatalı kurgulardan kaynaklanan adaptasyon maliyetlerini ve yüksek kullanıcı kaybı (churn) riskini minimize eder.
- Sürdürülebilir Performans ve Etik Optimizasyon: Motivasyon, sadece kısa vadeli dopamin patlamalarıyla değil, etik sınırlar ve kullanıcı esenliği gözetilerek sistematik olarak optimize edilir. Sonuç: rastlantısal değil, mühendislik yapılmış bir kurumsal bağlılıktır.
Oyunlaştırma artık yalnızca sezgisel bir tasarım pratiği değil; ölçülebilir, optimize edilebilir ve öngörülebilir bir davranış mühendisliği disiplinine dönüşmektedir. Bu dönüşümle birlikte tasarımcıların rolü de evrilmekte; artık yalnızca deneyim kurgulayan değil, kullanıcı davranışını modelleyen, simüle eden ve sürekli optimize eden sistem mimarları haline gelmektedirler.
Gamfed Türkiye Beray Çinçin‘in katkılarıyla yazılmıştır.













Yorum gönder